0x01 (기초 코드 작성요령1)
공간복잡도 입력의 크기와 문제를 해결하는데 필요한 공가느이 상관관계 문제를 풀때 크게 중요하지 않지만
512MB = 1.2억개의 int 를 기억해두면 좋음 1.2억개를 넘는 배열이면 틀림
실수의 저장/연산 과정에서 반드시 오차가 발생할 수 밖에 없다.
0.1+ 0.1 +0.1 != 0.3
실수자료형을 쓸 때는 반드시 double을 쓸 것 그래야지 오차가 안 생김
0x02 (기초 코드 작성요령2)
STL을 함수 인자로 넘길 때
참조자로해야지 시간복잡도가 o(N)이 된다.
char* 보다 string이 훨씬 편함
cin 공백을 포함한 문자열을 입력 받을때
getline(cin, s); 타입이 c++ string이어야함.
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0) c++ stream만 쓰는것임 c,와 c++ stream간의 동기화를 끊는 명령임.
printf와 scanf 를 섞어쓰면 절대 안됌.
endl 절대 쓰지마 '\n'만 써라.
디버거 굳이 안쓰는거 추천함 but 써도 상관은 없음.
차라리 중간중간 출력해보는거 추천.
0x03 (배열)
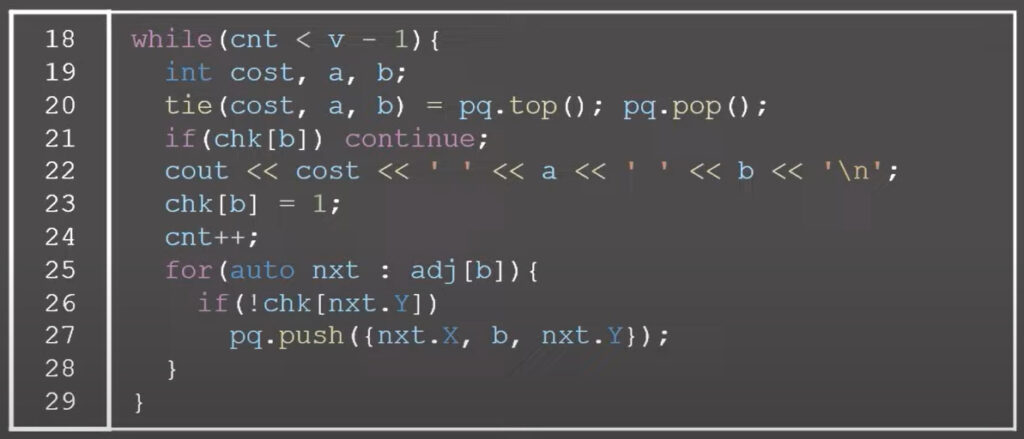
배열을 특정값으로 초기화 할 때 for문 돌리기 무난
int a[21];
int b[21][21];
fill(a, a+21, 0); // a
for(int i=0; i <21; i++)
{
fill(b[i], b[i]+21,0);
}vector
range-based for loop
for(int e :v1) // e에 v1원소들이 하나씩 들어가는 for문 int&e =v1은 원본이 그대로 복사되므로 e값을 바꾸면 v1도 바뀜
cout<< e << ' ';
vector v1(3, 5); // {5,5,5};
cout << v1.size() << '\n'; // 3
v1.push_back(7); // {5,5,5,7};
vector v2(2); // {0,0};
v2.insert(v2.begin()+1, 3); // {0,3,0};
vector v3 = {1,2,3,4}; // {1,2,3,4}
v3.erase(v3.begin()+2); // {1,2,4};
vector v4; // {}
v4 = v3; // {1,2,4}
cout << v4[0] << v4[1] << v4[2] << '\n';
v4.pop_back(); // {1,2}
v4.clear(); // {}0x04 (리스트)
아래코드를 활용할 수 있으면 문제 없다고 생각함 STL을 사용하지 못하는 코딩테스트의 경우 직접 만들어야 하지만 그런경우가 거의
없다고 함. 당장은 이걸 사용하는거에 만족하기로함.
list<int> L = {1,2}; // 1 2
list<int>::iterator t = L.begin(); // t는 1을 가리키는 중
L.push_front(10); // 10 1 2
cout << *t << '\n'; // t가 가리키는 값 = 1을 출력
L.push_back(5); // 10 1 2 5
L.insert(t, 6); // t가 가리키는 곳 앞에 6을 삽입, 10 6 1 2 5
t++; // t를 1칸 앞으로 전진, 현재 t가 가리키는 값은 2
t = L.erase(t); // t가 가리키는 값을 제거, 그 다음 원소인 5의 위치를 반환
// 10 6 1 5, t가 가리키는 값은 5
cout << *t << '\n'; // 5
for(auto i : L) cout << i << ' ';
cout << '\n';
for(list<int>::iterator it = L.begin(); it != L.end(); it++)
cout << *it << ' ';0x05 (스택) FILO(First Input Last Out)
STL 원소접근 불가 직접구현시 스택은 배열 or 연결리스트를 이용해서 구현가능 일반적으로 배열을 통해서 구현
STL stack사용하여 가능
stack S;
S.push(10); // 10
S.push(20); // 10 20
S.push(30); // 10 20 30
cout << S.size() << '\n'; // 3
if(S.empty()) cout << "S is empty\n";
else cout << "S is not empty\n"; // S is not empty
S.pop(); // 10 20
cout << S.top() << '\n'; // 20
S.pop(); // 10
cout << S.top() << '\n'; // 10
S.pop(); // empty
if(S.empty()) cout << "S is empty\n"; // S is empty
cout << S.top() << '\n'; // runtime error 발생0x06 (queue) FIFO(First Input First Out)
STL 사용시 원소접근 불가
queue Q;
Q.push(10); // 10
Q.push(20); // 10 20
Q.push(30); // 10 20 30
cout << Q.size() << '\n'; // 3
if(Q.empty()) cout << "Q is empty\n";
else cout << "Q is not empty\n"; // Q is not empty
Q.pop(); // 20 30
cout << Q.front() << '\n'; // 20
cout << Q.back() << '\n'; // 30
Q.push(40); // 20 30 40
Q.pop(); // 30 40
cout << Q.front() << '\n'; // 300x07 (deque)
STL 원칙적으로는 시작과 끝 이외의 원소접근 불가능하나 STL 상으로 원소 접근 가능
vector의 기능을 전부포함하고 심지어 원소의 앞쪽에서 접근가능함..
둘이 어떤걸 쓸지 결정할때 조건은 앞뒤에서 모두원소를 제거하면 덱을쓰고 앞에서 원소제걸할일이없으면 굳이 덱을쓰지말아라
deque DQ;
DQ.push_front(10); // 10
DQ.push_back(50); // 10 50
DQ.push_front(24); // 24 10 50
for(auto x : DQ)cout<<x;
cout << DQ.size() << '\n'; // 3
if(DQ.empty()) cout << "DQ is empty\n";
else cout << "DQ is not empty\n"; // DQ is not empty
DQ.pop_front(); // 10 50
DQ.pop_back(); // 10
cout << DQ.back() << '\n'; // 10
DQ.push_back(72); // 10 72
cout << DQ.front() << '\n'; // 10
DQ.push_back(12); // 10 72 12
DQ[2] = 17; // 10 72 17
DQ.insert(DQ.begin()+1, 33); // 10 33 72 17
DQ.insert(DQ.begin()+4, 60); // 10 33 72 17 60
for(auto x : DQ) cout << x << ' ';
cout << '\n';
DQ.erase(DQ.begin()+3); // 10 33 72 60
cout << DQ[3] << '\n'; // 60
DQ.clear(); // DQ의 모든 원소 제거0x08 스택의 활용(수식의 괄호 쌍)
괄호쌍이 만날때 해당쌍을 비워주는 방식으로 진행하다보면 결과적으로 스택이 모두비어있게됌 그 조건일때 괄호쌍 조건을 만족한다. 이 원리를 이용해서 알고리즘을 구현하면됌.
https://github.com/encrypted-def/basic-algo-lecture/blob/master/0x08/4949.cpp
위 링크 코드 참고
0x09 BFS(Breadth First Search)
// 큐를 써서 너비탐색
:다차원 배열에서 각 칸을 방문할 때 너비를 우선으로 방문하는 알고리즘
BFS알고리즘을 이해했다면 암기하고 있는것이 좋음. 이해했으므로 하기 알고리즘 코드를 암기하였음.
BFS알고리즘을 이해했다면 암기하고 있는것이 좋음. 이해했으므로 하기 알고리즘 코드를 암기하였음.
#include <bits/stdc++.h>
using namespace std;
#define X first
#define Y second // pair에서 first, second를 줄여서 쓰기 위해서 사용
int board[502][502] =
{{1,1,1,0,1,0,0,0,0,0},
{1,0,0,0,1,0,0,0,0,0},
{1,1,1,0,1,0,0,0,0,0},
{1,1,0,0,1,0,0,0,0,0},
{0,1,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0,0} }; // 1이 파란 칸, 0이 빨간 칸에 대응
bool vis[502][502]; // 해당 칸을 방문했는지 여부를 저장
int n = 7, m = 10; // n = 행의 수, m = 열의 수
int dx[4] = {1,0,-1,0};
int dy[4] = {0,1,0,-1}; // 상하좌우 네 방향을 의미
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
queue<pair<int,int> > Q;
vis[0][0] = 1; // (0, 0)을 방문했다고 명시
Q.push({0,0}); // 큐에 시작점인 (0, 0)을 삽입.
while(!Q.empty()){
pair<int,int> cur = Q.front(); Q.pop();
cout << '(' << cur.X << ", " << cur.Y << ") -> ";
for(int dir = 0; dir < 4; dir++){ // 상하좌우 칸을 살펴볼 것이다.
int nx = cur.X + dx[dir];
int ny = cur.Y + dy[dir]; // nx, ny에 dir에서 정한 방향의 인접한 칸의 좌표가 들어감
if(nx < 0 || nx >= n || ny < 0 || ny >= m) continue; // 범위 밖일 경우 넘어감
if(vis[nx][ny] || board[nx][ny] != 1) continue; // 이미 방문한 칸이거나 파란 칸이 아닐 경우
vis[nx][ny] = 1; // (nx, ny)를 방문했다고 명시
Q.push({nx,ny});
}
}
}
BFS를 돌 때 큐에 쌓이는 원소들은 결국 반드시 거리순(오름차순)으로 쌓이게 되는 원리이다.
0x0A DFS(Depth First Search)
스택을 써서 깊이탐색
:다차원 배열에서 각 칸을 방문할 때 깊이를 우선으로 방문하는 알고리즘.
현재 보는 칸으로부터 추가되는 인접한 칸은 거리가 현재 보는 칸보다 1만큼 더 떨어져있다.는
성질이 DFS에서는 성립하지 않음. 거리계산에서는 DFS사용 X 결국 다차원 배열에서 굳이 BFS대신
DFS를 써야하는 일이 없다. Flood Fill은 BFS와 DFS중에서 어느 것을 써도 상관없음.
0x0B 재귀
귀납적 방식
1번 도미노가 쓰러진다. K번 도미노가 쓰러진면 K+1번 도미노도 쓰러진다.
재귀는 반복문 보다 시간적 메모리적으로 손해이지만 반복문이 너무 복잡해지면 그땐 재귀를 쓰는게 좋다.
절차지향적인 사고로 생각하지 말아야한다. 절차지향적인 사고로 생각하다보면 무간지옥에 빠진다.
딱 귀납적으로 생각해야 한다. 귀납적인 사고를 받아 들여야 한다.
귀납적 사고 : 1번 도미노가 쓰러진다. K번 도미노가 쓰러진면 K+1번 도미노도 쓰러진다.
순서
1.함수의정의
2.base condition
3.재귀 식
재귀의 응용부분은 우선 안풀리기도하고 이해하는데 시간이 걸려 넘어갔음.
0x0C 백트래킹
현재 상태에서 가능한 모든 후보군을 따라 들어가며 탐색하는 알고리즘
백트래킹(Backtracking)은 DFS(Depth-First Search)의 한 종류로, 어떤 문제에서 해를 찾는 도중 해가 아니어서 더 이상 진행할 필요가 없게 되는 경우, 이전 단계로 돌아가서 다시 해를 찾아가는 방법입니다.
이를 위해 스택(Stack)을 사용하며, 문제의 제약 조건(Constraint)에 따라 해를 찾아가다가, 더 이상 진행할 수 없으면 이전 단계로 돌아가서 다시 시도합니다.
DFS와 백트래킹의 차이는 DFS는 모든 경우를 다 탐색하는 방법이고, 백트래킹은 불필요한 탐색을 줄이기 위해 해가 될 가능성이 없는 노드를 미리 탐색하지 않고 건너뛰는 기법입니다.
DFS는 탐색 중간에 어떤 조건이 맞을 때 그 자식 노드들을 모두 방문하는 것이지만, 백트래킹은 불필요한 경로를 미리 차단하여 중간에 가지치기를 하기 때문에 효율성이 좋습니다.
재귀를 써야하나 기본적인 템플릿이있고 형식이 비슷하여 해볼만한 느낌이든다.
아래가 가장 기본적인 문제와 템플릿
백준 15649 N과 M(1)
#include <bits/stdc++.h>
using namespace std;
int n,m;
int arr[10];
bool isused[10];
void func(int k){ // 현재 k개까지 수를 택했음.
if(k == m){ // m개를 모두 택했으면
for(int i = 0; i < m; i++)
cout << arr[i] << ' '; // arr에 기록해둔 수를 출력
cout << '\n';
return;
}
for(int i = 1; i <= n; i++){ // 1부터 n까지의 수에 대해
if(!isused[i]){ // 아직 i가 사용되지 않았으면
arr[k] = i; // k번째 수를 i로 정함
isused[i] = 1; // i를 사용되었다고 표시
func(k+1); // 다음 수를 정하러 한 단계 더 들어감
isused[i] = 0; // k번째 수를 i로 정한 모든 경우에 대해 다 확인했으니 i를 이제 사용되지않았다고 명시함.
}
}
}
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
func(0);
}0x15 해시
해시 자료구조는 키에 대응하는 값을 저장하는 자료구조이다.

연결리스트로 value값을 넣고 발생하는 충돌을 회피하기위한 기법으로 첫번째는 Chaining이 사용된다.
(실제 C++ STL에서 사용되는 기법)

#include <bits/stdc++.h>
using namespace std;
void unordered_set_example(){
unordered_set<int> s;
s.insert(-10); s.insert(100); s.insert(15); // {-10, 100, 15}
s.insert(-10); // {-10, 100, 15} // 중복허용 X
cout << s.erase(100) << '\n'; // {-10, 15}, 1반환
cout << s.erase(20) << '\n'; // {-10, 15}, 0반환
if(s.find(15) != s.end()) cout << "15 in s\n";
else cout << "15 not in s\n";
cout << s.size() << '\n'; // 2
cout << s.count(50) << '\n'; // 0반환
for(auto e : s) cout << e << ' ';
cout << '\n';
}
void unordered_multiset_example(){ // 위와 차이점은 중복허용 가능
unordered_multiset<int> ms;
ms.insert(-10); ms.insert(100); ms.insert(15); // {-10, 100, 15}
ms.insert(-10); ms.insert(15);// {-10, -10, 100, 15, 15}
cout << ms.size() << '\n'; // 5
for(auto e : ms) cout << e << ' ';
cout << '\n';
cout << ms.erase(15) << '\n'; // {-10, -10, 100}, 2
ms.erase(ms.find(-10)); // {-10, 100}
ms.insert(100); // {-10, 100, 100}
cout << ms.count(100) << '\n'; // 2
}
void unordered_map_example(){
unordered_map<string, int> m;
m["hi"] = 123;
m["bkd"] = 1000;
m["gogo"] = 165; // ("hi", 123), ("bkd", 1000), ("gogo", 165)
cout << m.size() << '\n'; // 3
m["hi"] = -7; // ("hi", -7), ("bkd", 1000), ("gogo", 165)
if(m.find("hi") != m.end()) cout << "hi in m\n";
else cout << "hi not in m\n";
m.erase("bkd"); // ("hi", 123), ("gogo", 165)
for(auto e : m)
cout << e.first << ' ' << e.second << '\n';
}해시를 직접 구현 하는 방법에는 두가지가 있습니다.
- chaining
- Open Addressing
1번 같은 경우 강의를 보고 따라 해보았지만 이해하기 상당하기 어려웠고 2번은 우선 패스 하였다.
0X16 이진 검색 트리
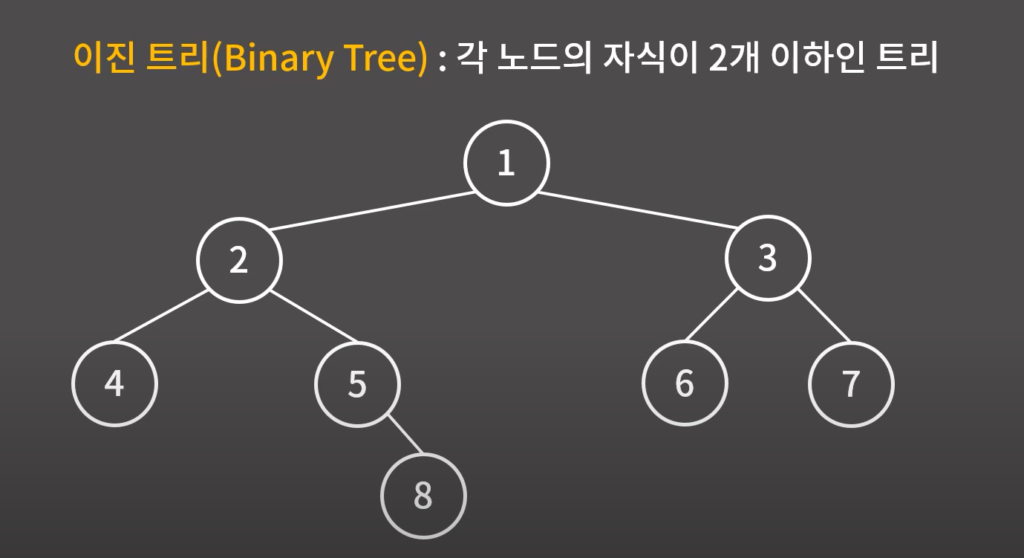
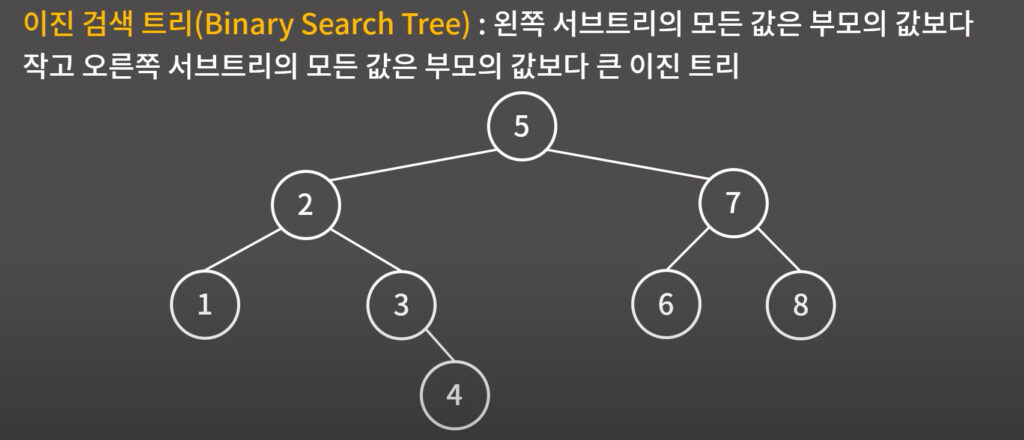
STL(st, multiset, map)
#include <bits/stdc++.h>
using namespace std;
void set_example(){
set<int> s;
s.insert(-10); s.insert(100); s.insert(15); // {-10, 15, 100}
s.insert(-10); // {-10, 15, 100}
cout << s.erase(100) << '\n'; // {-10, 15}, 1
cout << s.erase(20) << '\n'; // {-10, 15}, 0
if(s.find(15) != s.end()) cout << "15 in s\n";
else cout << "15 not in s\n";
cout << s.size() << '\n'; // 2
cout << s.count(50) << '\n'; // 0
for(auto e : s) cout << e << ' ';
cout << '\n';
s.insert(-40); // {-40, -10, 15}
set<int>::iterator it1 = s.begin(); // {-40(<-it1), -10, 15}
it1++; // {-40, -10(<-it1), 15}
auto it2 = prev(it1); // {-40(<-it2), -10, 15}
it2 = next(it1); // {-40, -10, 15(<-it2)}
advance(it2, -2); // {-40(<-it2), -10, 15}
auto it3 = s.lower_bound(-20); // {-40, -10(<-it3), 15}
auto it4 = s.find(15); // {-40, -10, 15(<-it4)}
cout << *it1 << '\n'; // -10
cout << *it2 << '\n'; // -40
cout << *it3 << '\n'; // -10
cout << *it4 << '\n'; // 15
}
void multiset_example(){
multiset<int> ms;
// {-10, 15, 100}
ms.insert(-10); ms.insert(100); ms.insert(15); // {-10, -10, 15, 15, 100}
ms.insert(-10); ms.insert(15);
cout << ms.size() << '\n'; // 5
for(auto e : ms) cout << e << ' ';
cout << '\n';
cout << ms.erase(15) << '\n'; // {-10, -10, 100}, 2
ms.erase(ms.find(-10)); // {-10, 100}
ms.insert(100); // {-10, 100, 100}
cout << ms.count(100) << '\n'; // 2
auto it1 = ms.begin(); // {-10(<-it1), 100, 100}
auto it2 = ms.upper_bound(100); // {-10, 100, 100} (<-it2)
auto it3 = ms.find(100); // {-10, 100(<-it3), 100} // 100중에서 아무거나 반환하기 때문에 가장 첫번째 값을 반환하려면 lower_bound를 써야한다.
cout << *it1 << '\n'; // -10
cout << (it2 == ms.end()) << '\n'; // 1
cout << *it3 << '\n'; // 100
}
void map_example(){
map<string, int> m;
m["hi"] = 123;
m["bkd"] = 1000;
m["gogo"] = 165; // ("bkd", 1000), ("gogo", 165), ("hi", 123)
cout << m.size() << '\n'; // 3
m["hi"] = -7; // ("bkd", 1000), ("gogo", 165), ("hi", -7)
if(m.find("hi") != m.end()) cout << "hi in m\n";
else cout << "hi not in m\n";
m.erase("bkd"); // ("gogo", 165), ("hi", 123)
for(auto e : m)
cout << e.first << ' ' << e.second << '\n';
auto it1 = m.find("gogo");
cout << it1->first << ' ' << it1->second << '\n'; // gogo 165
}
int main(){
set_example();
multiset_example();
map_example();
}- lower_bound(first, last, value) : [first, last) 범위에서 value보다 크거나 같은 첫번째 원소의 위치를 반환합니다. 존재하지 않으면 end() 위치를 반환 합니다.
- upper_bound(first, last, value) : [first, last) 범위에서 value보다 큰 첫번째 원소의 위치를 반환합니다. 존재하지 않으면 end() 위치를 반환 합니다.
0X17 우선순위 큐
#include <bits/stdc++.h>
using namespace std;
int heap[100005];
int sz = 0; // heap에 들어있는 원소의 수
void push(int x){
heap[++sz] = x;
int idx = sz;
while(idx != 1){
int par = idx/2;
if(heap[par] <= heap[idx]) break;
swap(heap[par], heap[idx]);
idx = par;
}
}
int top(){
return heap[1];
}
void pop(){
heap[1] = heap[sz--];
int idx = 1;
// 왼쪽 자식의 인덱스(=2*idx)가 size보다 크면 idx는 리프
while(2*idx <= sz){
int lc = 2*idx, rc = 2*idx+1; // 왼쪽 자식, 오른쪽 자식
int min_child = lc; // 두 자식 중 작은 인덱스를 담을 예정
if(rc <= sz && heap[rc] < heap[lc])
min_child = rc;
if(heap[idx] <= heap[min_child]) break;
swap(heap[idx],heap[min_child]);
idx = min_child;
}
}
void test(){
push(10); push(2); push(5); push(9); // {10, 2, 5, 9}
cout << top() << '\n'; // 2
pop(); // {10, 5, 9}
pop(); // {10, 9}
cout << top() << '\n'; // 9
push(5); push(15); // {10, 9, 5, 15}
cout << top() << '\n'; // 5
pop(); // {10, 9, 15}
cout << top() << '\n'; // 9
}
int main(void){
test();
}STL priority_queue
#include <bits/stdc++.h>
using namespace std;
int main(void){
priority_queue<int> pq; // 최대 힙
// priority_queue<int, vector<int>, greater<int>>로 선언시 최소 힙
pq.push(10); pq.push(2); pq.push(5); pq.push(9); // {10, 2, 5, 9}
cout << pq.top() << '\n'; // 10
pq.pop(); // {2, 5, 9}
cout << pq.size() << '\n'; // 3
if(pq.empty()) cout << "PQ is empty\n";
else cout << "PQ is not empty\n";
pq.pop(); // {2, 5}
cout << pq.top() << '\n'; // 5
pq.push(5); pq.push(15); // {2, 5, 5, 15}
cout << pq.top() << '\n'; // 15
}0x18강 그래프
인접 행렬
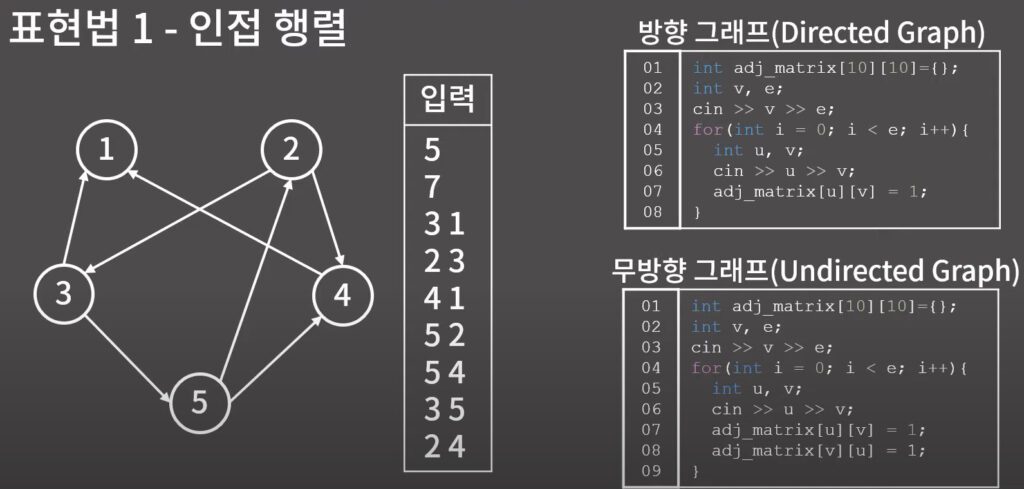
인접 리스트

인접 행렬과 인접 리스트 비교

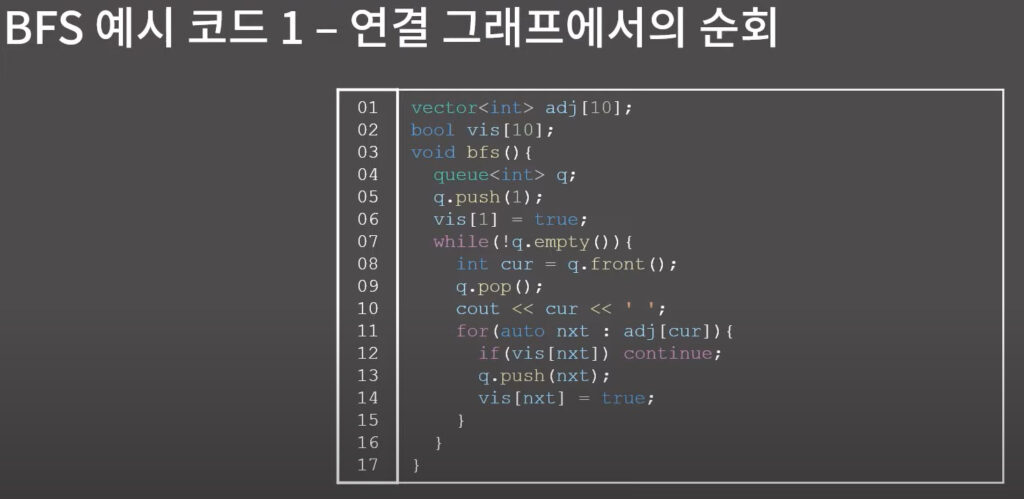
BFS 예시 코드 1- 연결 그래프에서의 순회
BFS 예시 코드 2 - 연결 그래프에서 1번 정점과의 거리
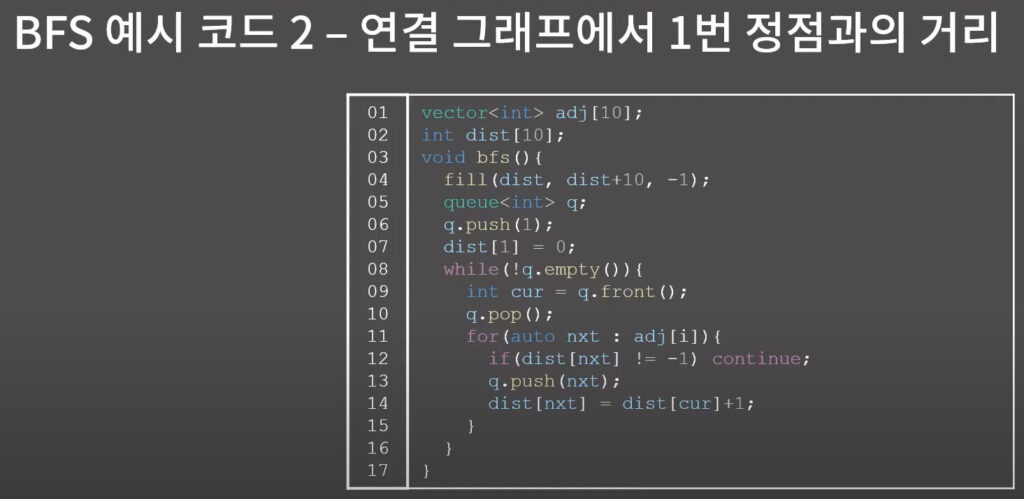
BFS 예시 코드 3 - 연결 그래프가 아닐 때 순회
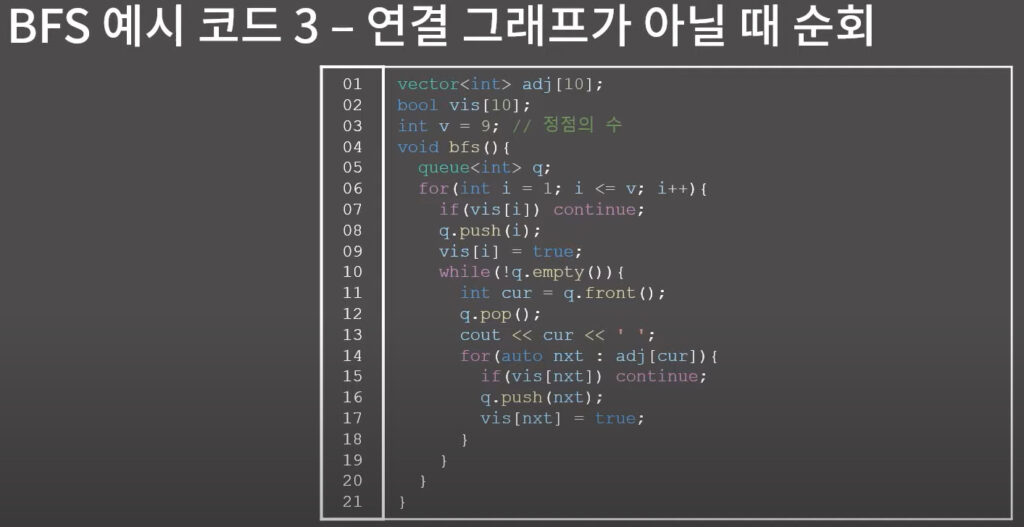
DFS 예시 코드 2 - 연결 그래프에서의 순회, 재귀
0x19강 트리
정의와 성질
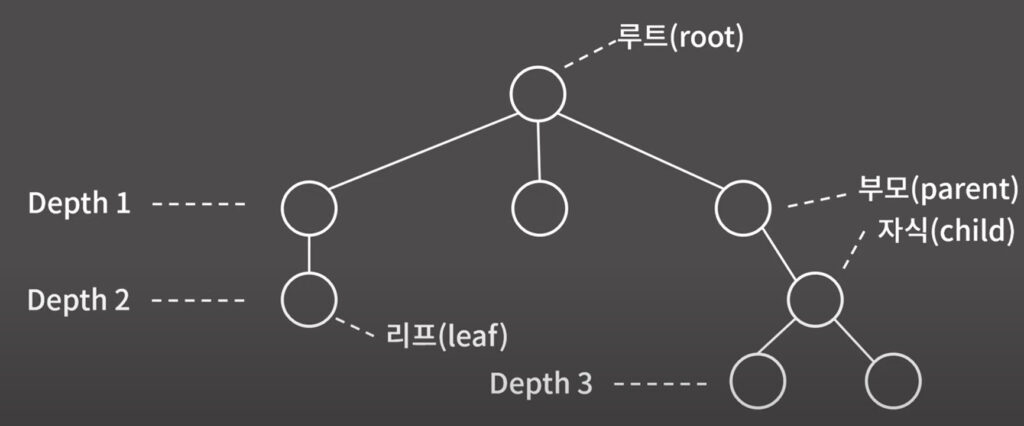
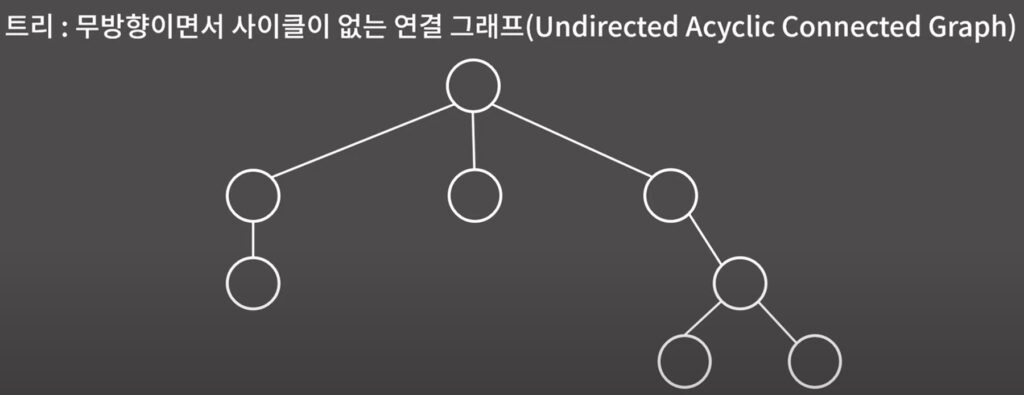
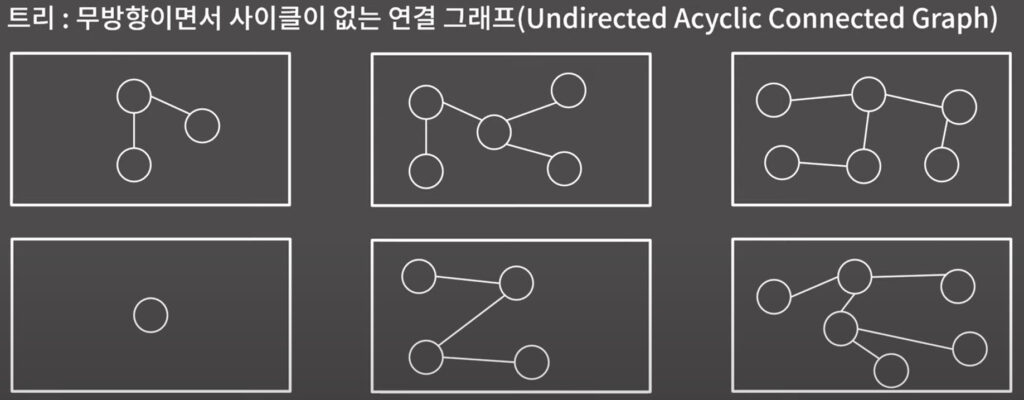


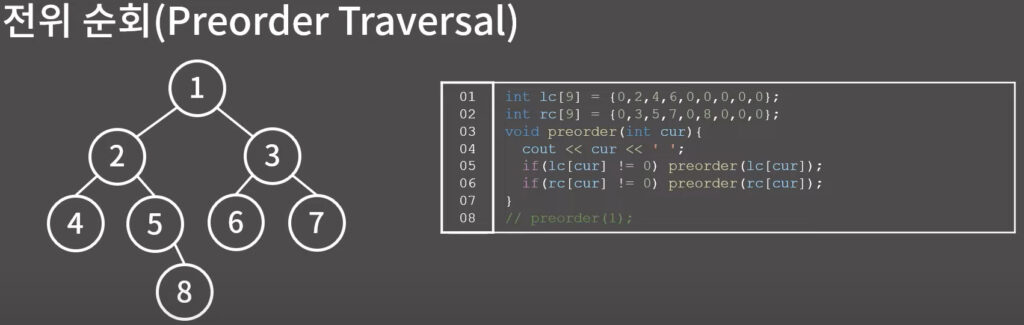
BFS, DFS





이진 트리의 순회



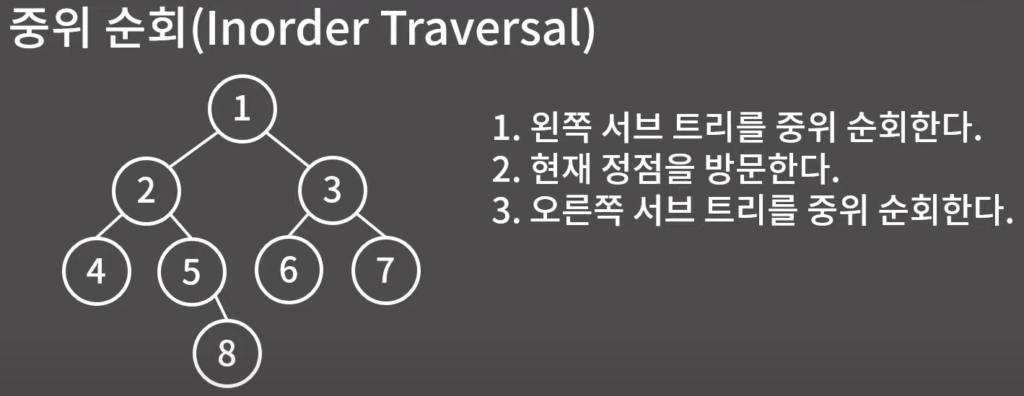

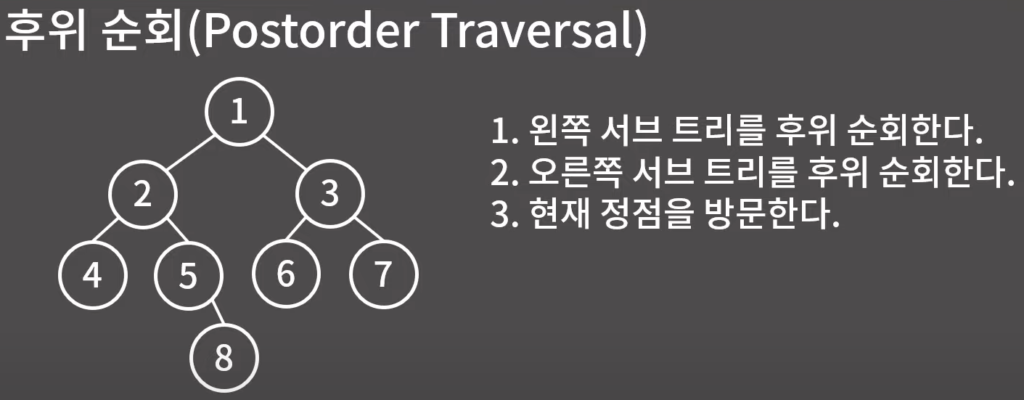
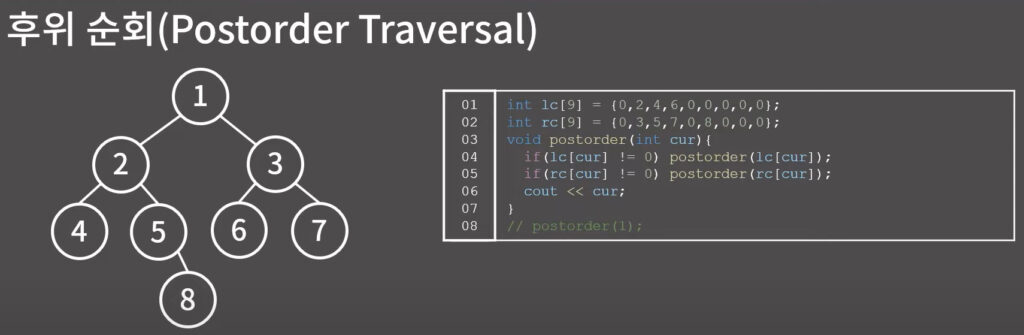
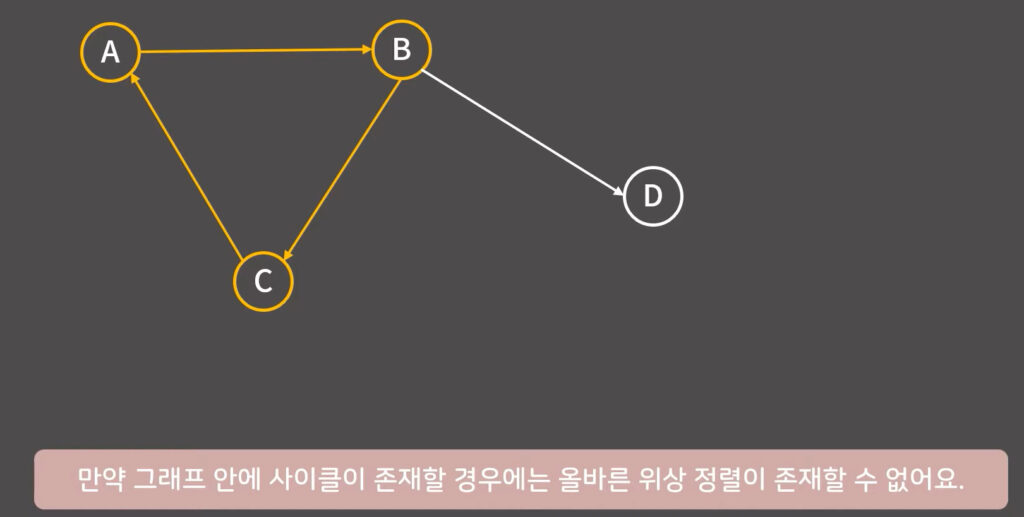
0x1A강 위상 정렬
0x00 알고리즘 설명

0x01 알고리즘 구현
Indgree 들어오는 간선이 없는 정점부터 탐색하고 해당 정점을 탐색하면 해당 정점에 연결된 간선과 같이 제거한다.



0x1B강 - 최소 신장 트리
0x00 정의 및 성질

왼쪽 그래프의 신장 트리는 오른쪽 그림이다.

왼쪽 그림에서 얻어낸 최소 신장 트리는 노란색으로 되어있는 트리이다. 간선의 합이 15로 같다.
0x01 크루스칼 알고리즘

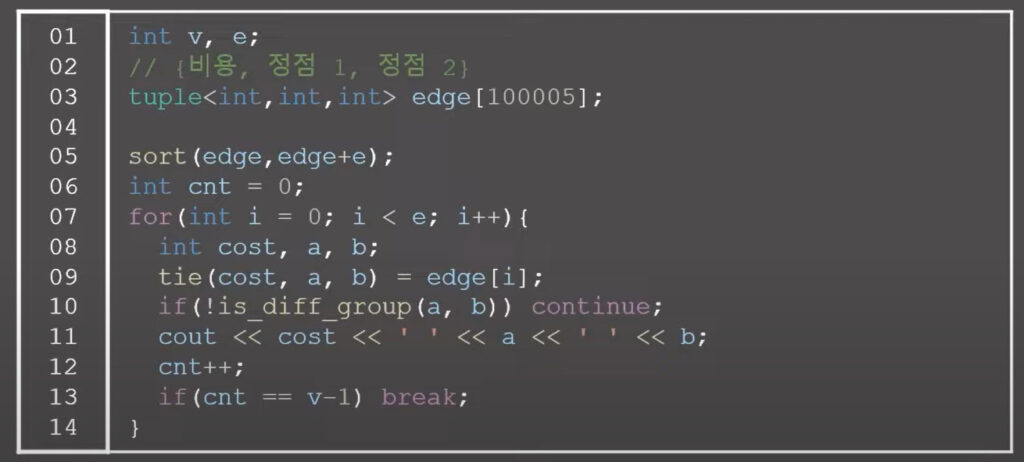
크루스칼 알고리즘을 이해하기 위해서는 유니온 파인드 알고리즘에 대한 지식이 선행 되어야 한다.
0x02 프림 알고리즘



0x03 연습 문제
0x1C강 - 플로이드 알고리즘
0x00 알고리즘 설명
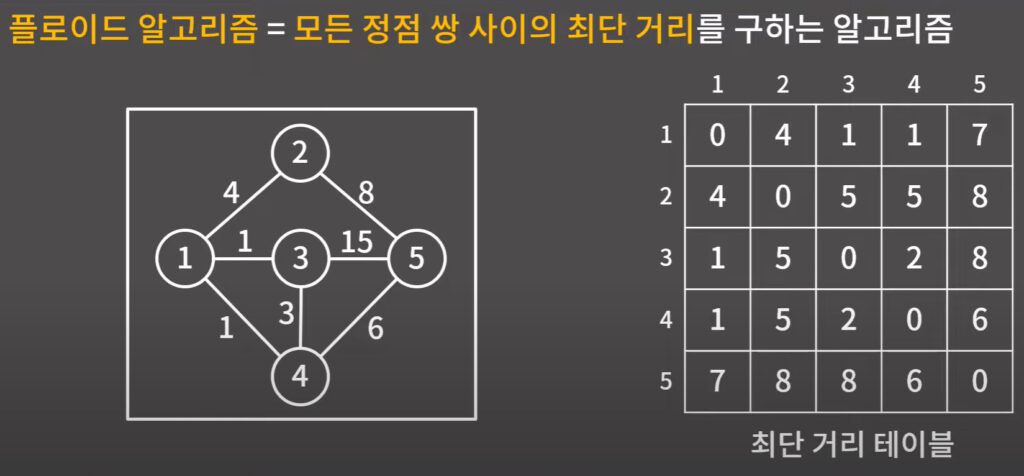
주어진 그래프에서 모든 정점 쌍 사이의 최단 거리를 구해주는 알고리즘
음수인 간선을 가지는 사이클이 존재하면 사용할 수 없음.
0x01 구현
백준 11404: 플로이드 (C++)
#include <bits/stdc++.h>
using namespace std;
const int INF = 0x3f3f3f3f;
int d[105][105];
int n, m;
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
for(int i = 1; i <= n; i++)
fill(d[i], d[i]+1+n, INF);
while(m--){
int a,b,c;
cin >> a >> b >> c;
d[a][b] = min(d[a][b], c);
}
for(int i = 1; i <= n; i++) d[i][i] = 0;
for(int k = 1; k <= n; k++)
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
d[i][j] = min(d[i][j], d[i][k]+d[k][j]);
for(int i = 1; i <= n; i++){
for(int j = 1; j <= n; j++){
if(d[i][j] == INF) cout << "0 ";
else cout << d[i][j] << ' ';
}
cout << '\n';
}
}0x02 경로 복원 방법
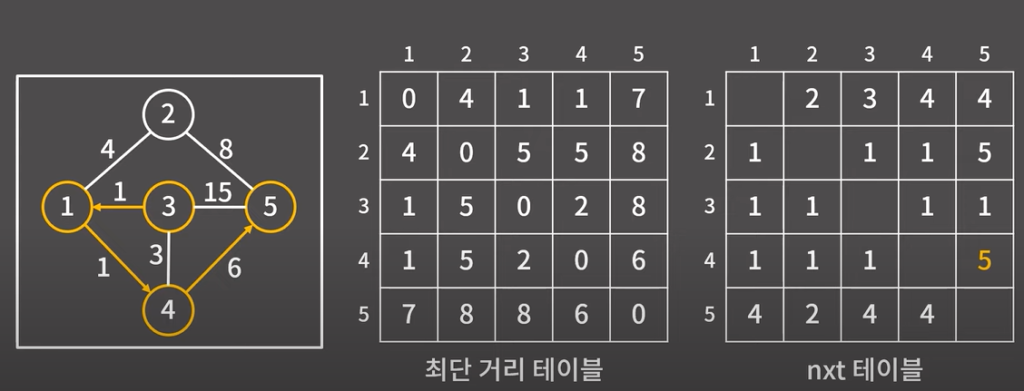
nxt 테이블은 예를 들어서 index가 [1][5] 라고 치면 [1][5] 의 경로로 가기위한 값들이 순서대로 들어있다. 뒤의값은 최종목적지이다.
[1][5] = 4, [4][5]=5 따라서 최단 경로는 1->4->5
백준 11780: 플로이드 (C++)
#include <bits/stdc++.h>
using namespace std;
const int INF = 0x3f3f3f3f;
int d[105][105];
int nxt[105][105];
int n, m;
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
for(int i = 1; i <= n; i++)
fill(d[i], d[i]+1+n, INF);
while(m--){
int a,b,c;
cin >> a >> b >> c;
d[a][b] = min(d[a][b], c);
nxt[a][b] = b;
}
for(int i = 1; i <= n; i++) d[i][i] = 0;
for(int k = 1; k <= n; k++)
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
if(d[i][k] + d[k][j] < d[i][j]){
d[i][j] = min(d[i][j], d[i][k]+d[k][j]);
nxt[i][j] = nxt[i][k];
}
for(int i = 1; i <= n; i++){
for(int j = 1; j <= n; j++){
if(d[i][j] == INF) cout << "0 ";
else cout << d[i][j] << ' ';
}
cout << '\n';
}
for(int i = 1; i <= n; i++){
for(int j = 1; j <= n; j++){
if(d[i][j] == 0 || d[i][j] == INF){
cout << "0\n";
continue;
}
vector<int> path;
int st = i;
while(st != j){
path.push_back(st);
st = nxt[st][j];
}
path.push_back(j);
cout << path.size() << ' ';
for(auto x : path) cout << x << ' ';
cout << '\n';
}
}
}
0x1D강 - 다익스트라 알고리즘
0x00 알고리즘 설명

0x01 구현

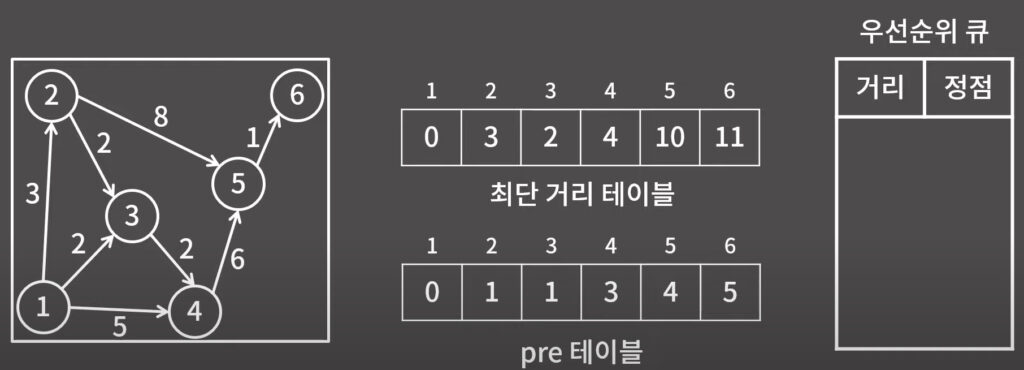
위 코드는 다익스트라 알고리즘의 원리를 이해하기 좋으나 O(V^2+E)의 시간 복잡도를 가지므로 효율성이떨어져서 사실상 잘 사용하지 않음. 아래와 같은 방법으로 시간 복잡도를 낮출 수 있다. 아래 방법은 O(ElogE)의 시간 복잡도를 가지고 실질적으로 더 많이 사용하는 알고리즘이다.

백준 1753번: 최단경로 (C++)


0x02 경로 복원 방법
11779번: 최소비용 구하기 2 (C++)

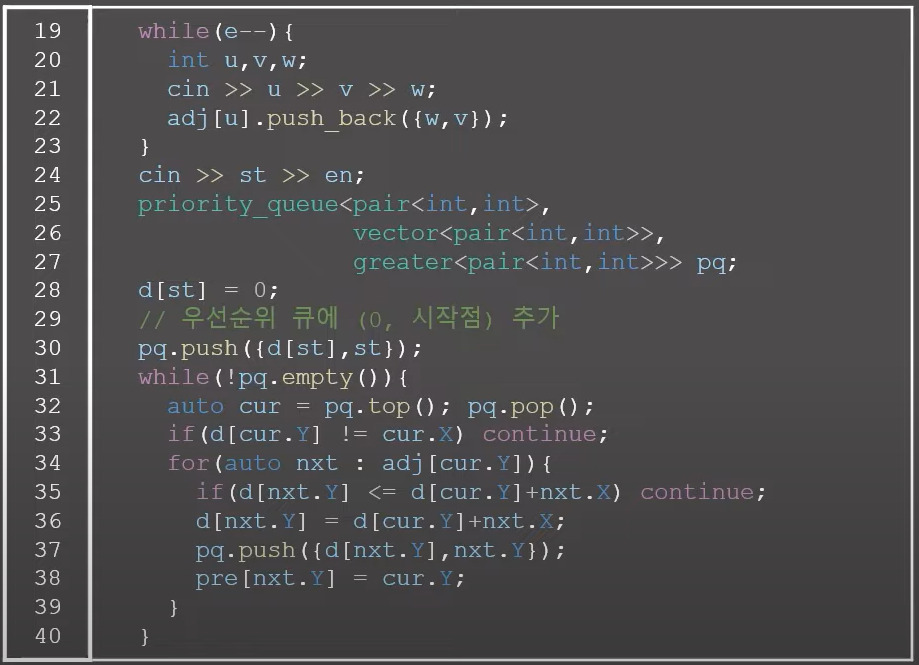

0x1E강 - KMP
0x00 알고리즘 설명


패턴 매칭 문제를 문자열 A안에 문자열 B가 들어있는지 판단하는 알고리즘이다.
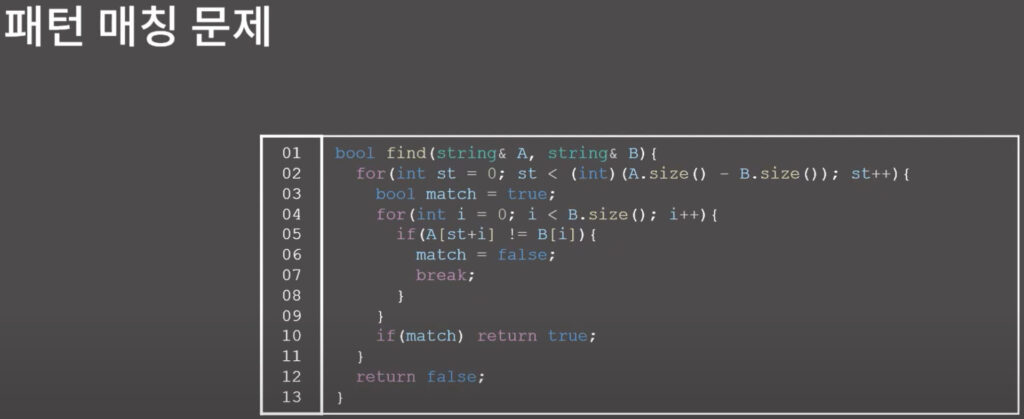
위 알고리즘은 시간 복잡도가 O(|A|*|B|)이다.
0x01 실패 함수
KMP알고리즘은 아래 설명과 같다.



현재 F(i)값을 구할 경우 F(i-1)만큼의 구간을 그대로 가져온 후 한글자가 일치하는지 확인한다. 일치하면
F(i) = F(i-1)+1이 된다.


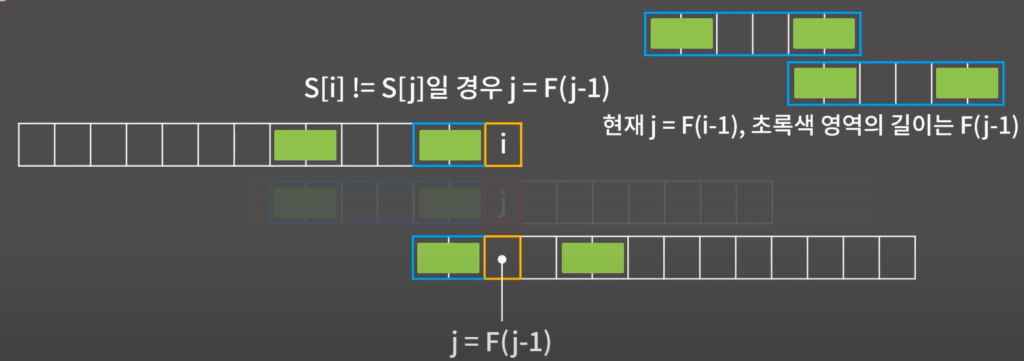
위 파란색 영역에 가운데 빈 영역은 문자열이 일치하지 않고 초록영역은 일치한다고 생각해보자 만약에 i=j=6이라면j=F(i-1)=2 가 되고 j=2가 된다.

0x02 KMP

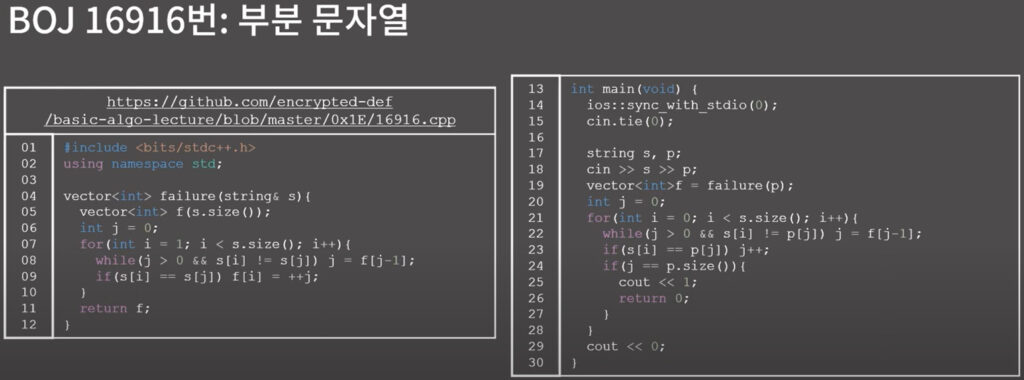

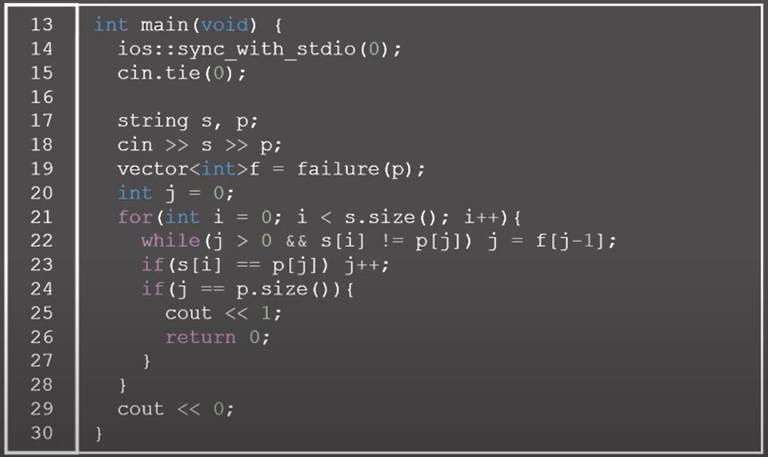
0x1F강 - 트라이
0x00 정의와 성질


0x01 기능과 구현


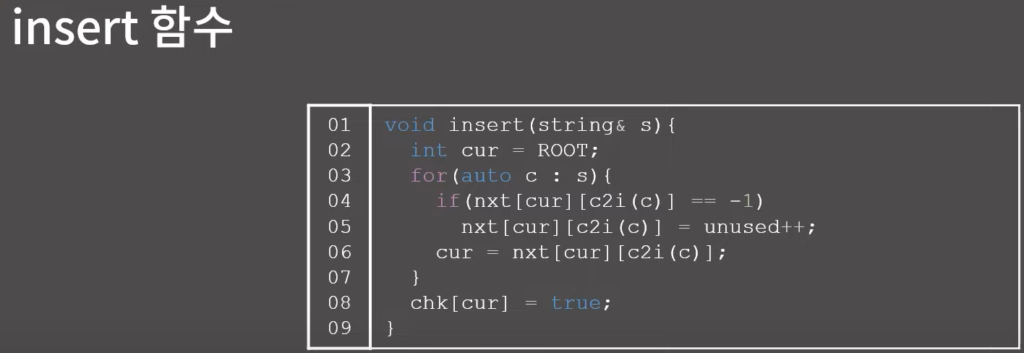
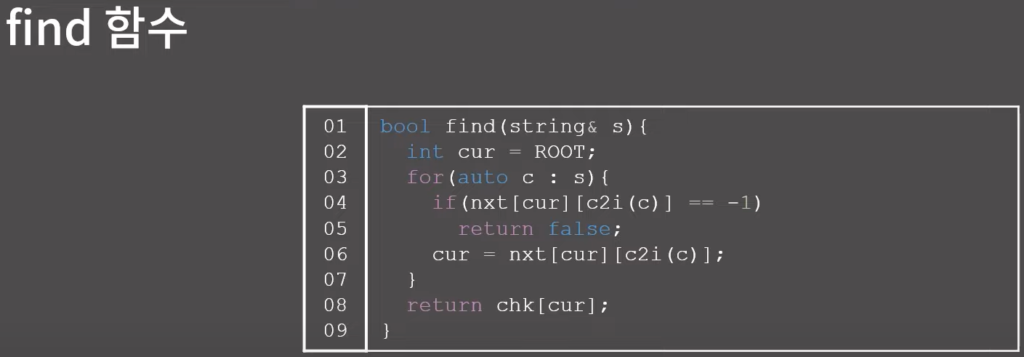
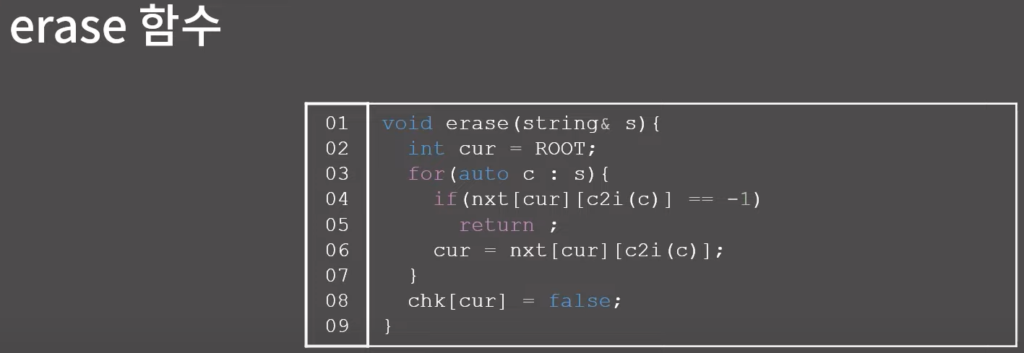
0x02 연습 문제
BOJ 14425번: 문자열 집합

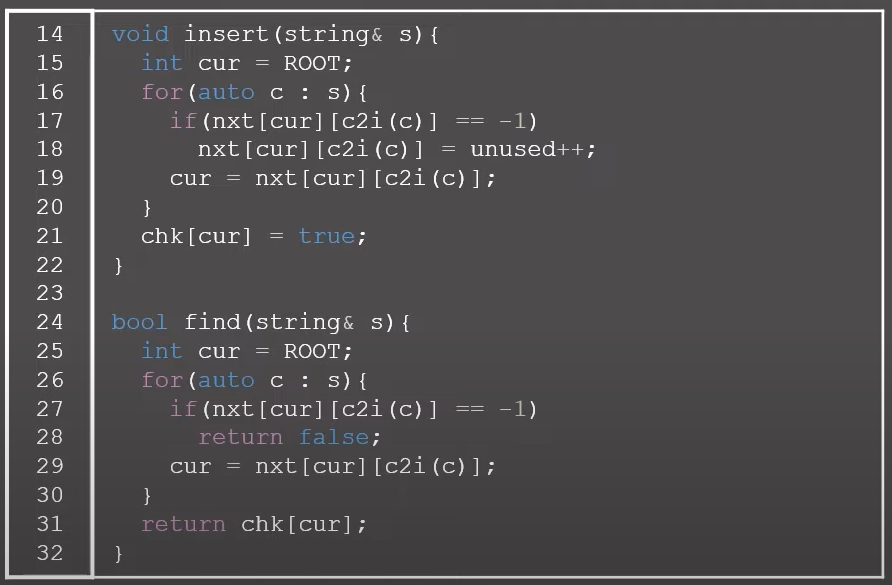
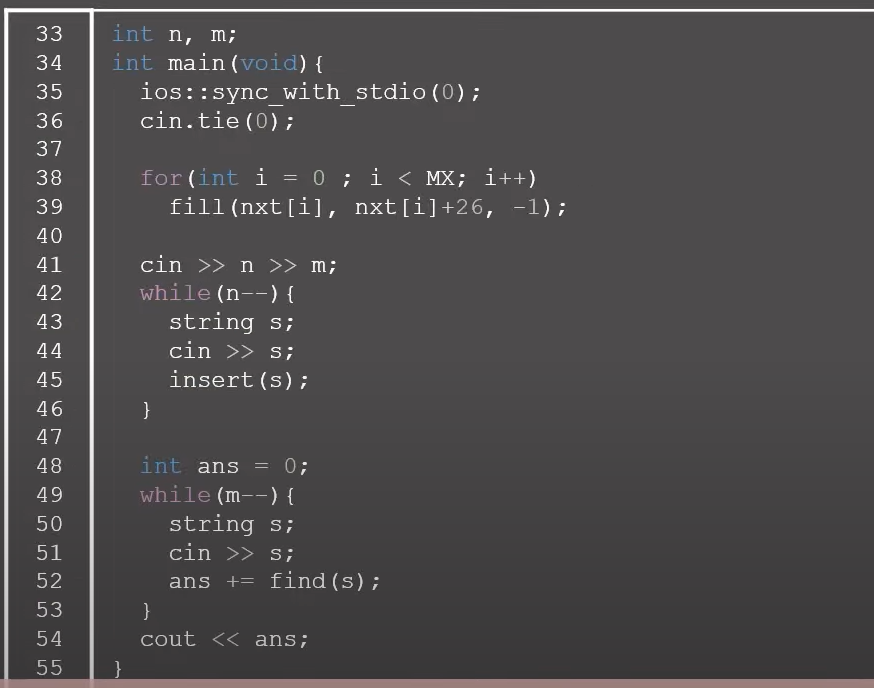
부록 A- 문자열 기초
0x00 C++ string




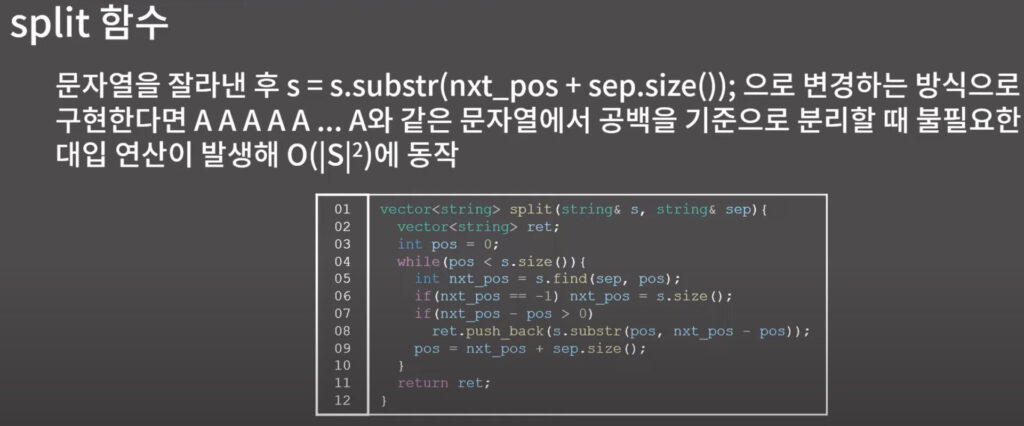


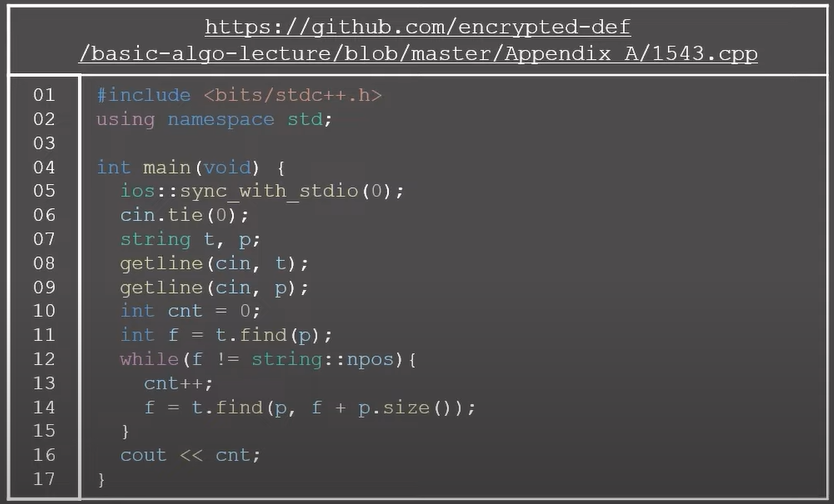
0x01 연습 문제 1 - 문서 검색
BOJ 1543번: 문서 검색
0x00 연습 문제 2 - 크로아티아 알파벳
'CS(Computer Science)지식 > [C++][코딩 테스트] 자료구조 및 알고리즘' 카테고리의 다른 글
| 백준 9375번: 패션왕 신해빈 [C++] (0) | 2024.01.31 |
|---|---|
| 백준 17219번: 비밀번호 찾기 [C++] (0) | 2024.01.31 |
| 백준 13414번: 수강신청 [C++] (0) | 2024.01.31 |
| 백준 1620번: 나는야 포켓몬 마스터 이다솜 [C++] (0) | 2024.01.31 |
| 백준 7785번: 회사에 있는 사람 [C++] (0) | 2024.01.31 |